Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue
Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue

Artículos relacionados

PROXMOX: Sustituir disco en almacenamiento CephFS
Hoy os voy a explicar como cambiar un disco duro estropeado en una hiperconvergencia con almacenamiento CephFS sobre Proxmox.
Mi Lab ha sufrido una baja, encima de las medianamente cara. Un disco WD Red NAS de 3TB ha tenido a bien “morirse” sin decir adiós ;P
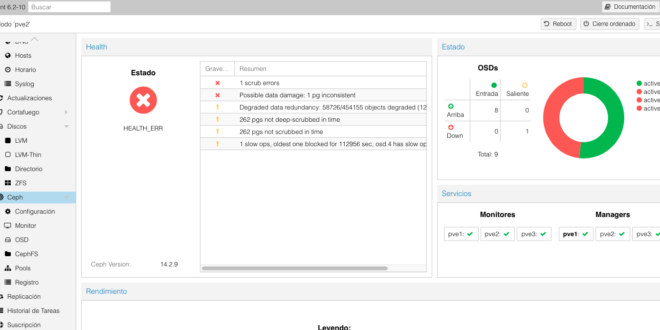
La verdad que tengo tres nodos, y las máquinas virtuales no han caído, y nada ha pasado salvo esta bonita pantalla con colores rojos y Zabbix pitando ante el problema:
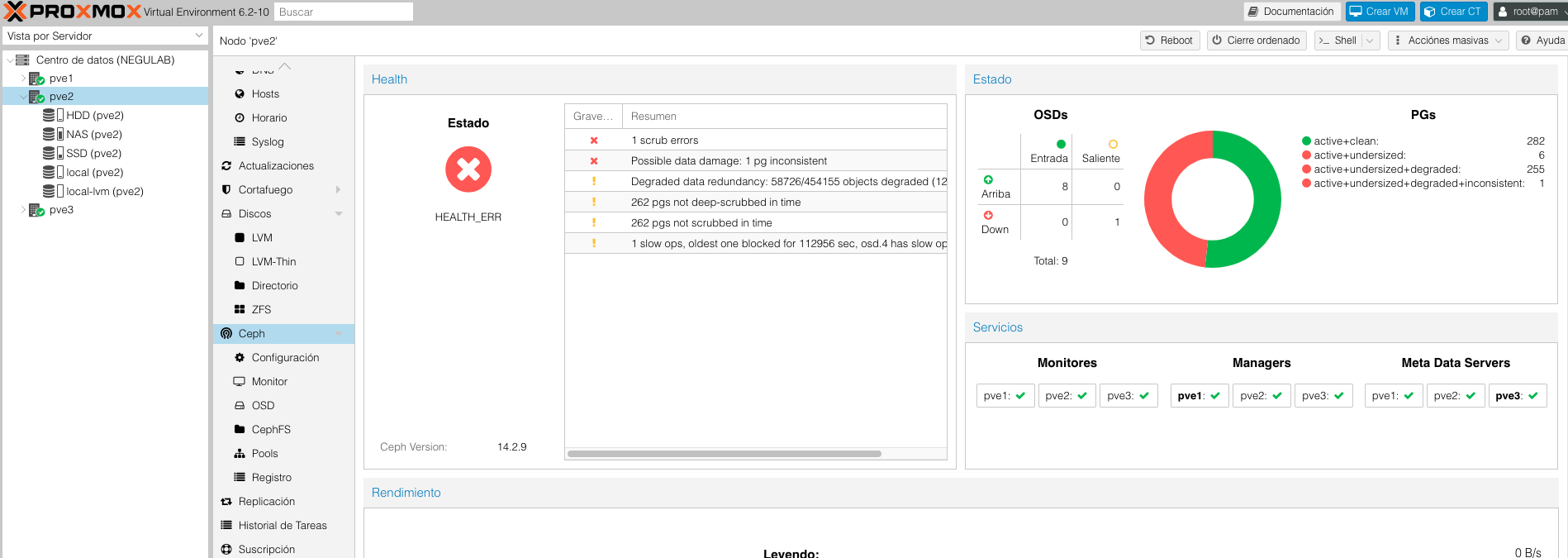
Podéis revisar el problema chequeando desde uno de los hosts de la siguiente forma:
|
1 |
ceph health |

Veremos tanto gráficamente, como vía comando, que tenemos un OSD caído:
|
1 |
ceph osd tree | grep -i down |
![]()
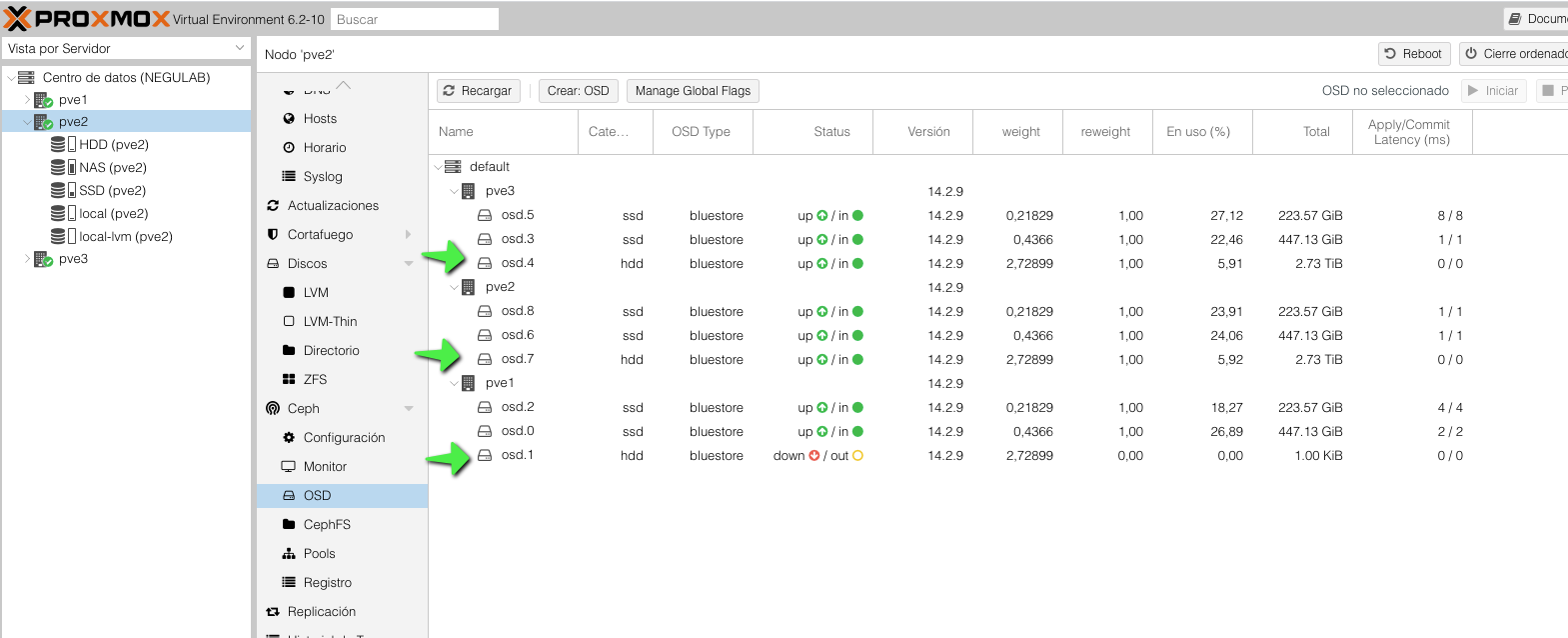
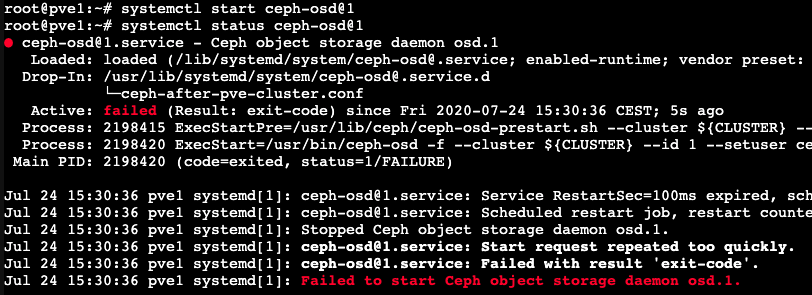
Aunque yo sé que no está trabajando, lo podemos validar, intentando levantarlo:
root@pve1:~# systemctl start ceph-osd@1
root@pve1:~# systemctl status ceph-osd@1

Así que me pongo manos a la obra para sustituirlo, lo primero liberar el nodo:
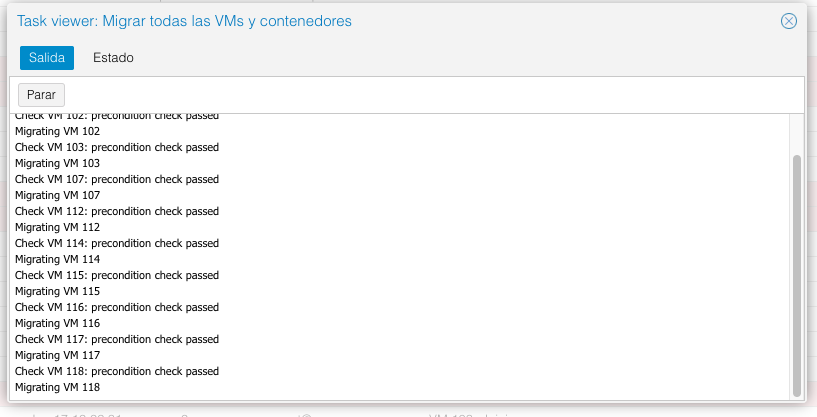
Realizar las validaciones, de que a nivel de sistema operativo tenemos todo lo que necesitamos, recogiendo datos y haciendo chequeos del disco averiado:
fdisk -l

smartctl -H /dev/sde

Vamos desmontando el disco de la siguiente forma:
root@pve1:~# ceph osd out osd.1
osd.1 is already out.
root@pve1:~# systemctl stop ceph-osd@1
root@pve1:~# ceph osd crush remove osd.1
removed item id 1 name 'osd.1' from crush map
root@pve1:~# ceph auth del osd.1
updated
root@pve1:~# ceph osd rm osd.1
removed osd.1
Desmontamos el OSD:
root@pve1:~# umount /var/lib/ceph/osd/ceph-1
Ponemos el cluster para que no se rellenen los datos
root@pve1:~# ceph osd set noout
noout is set
Cambiamos el disco averiado, apagando el host y colocando el sustituto:
root@pve1:~# shutdown -h now
Modificamos nuevamente el cluster:
root@pve1:~# ceph osd unset noout
noout is unset
Creamos el OSD nuevamente:
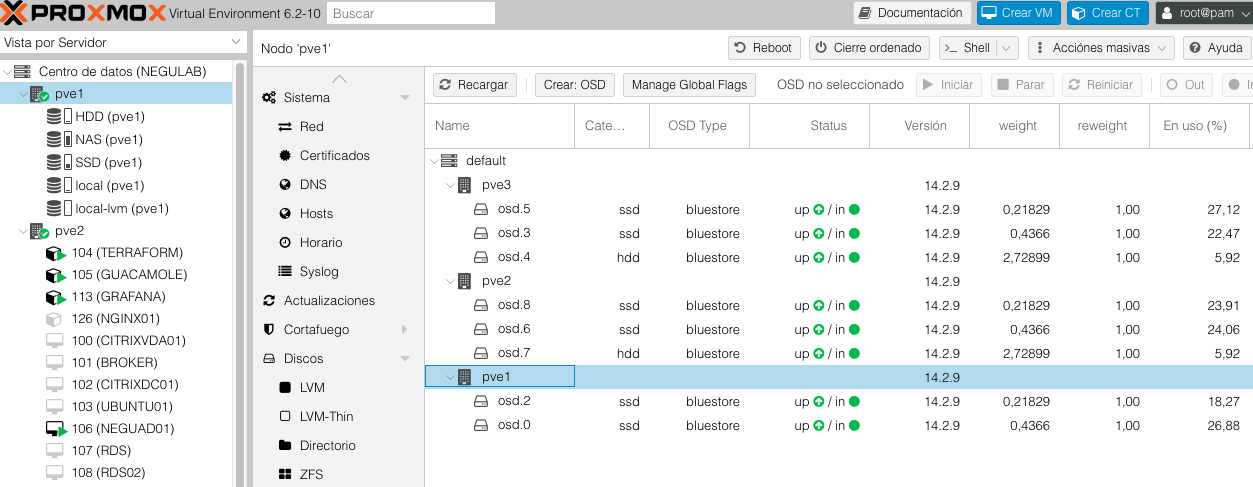
Pulsamos Crear:
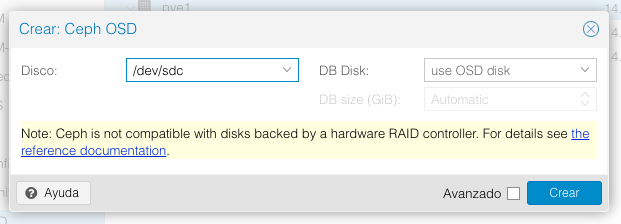
Y validamos que su estado el idóneo:
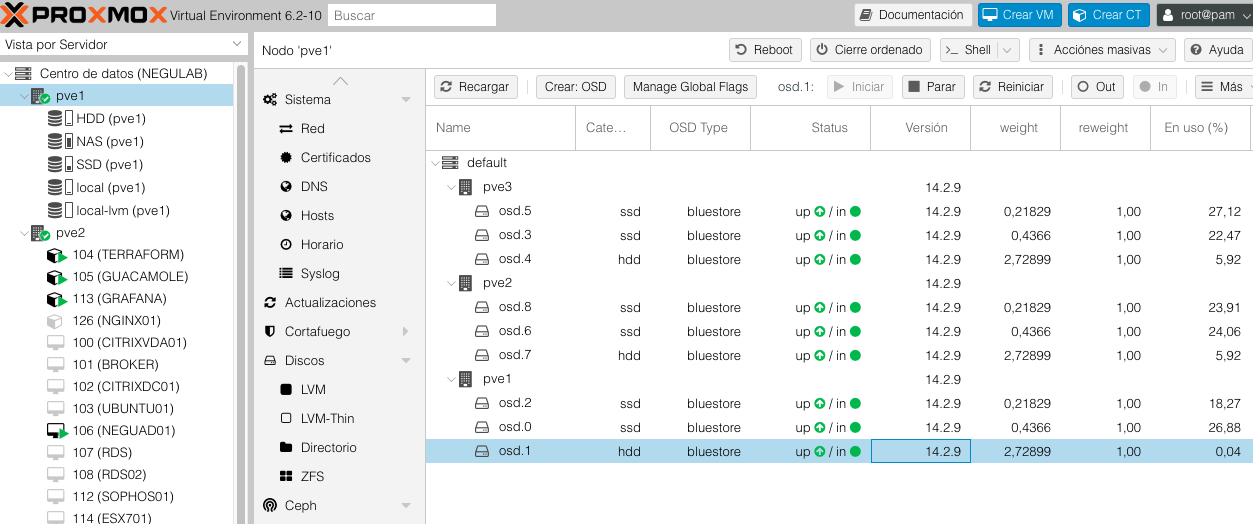
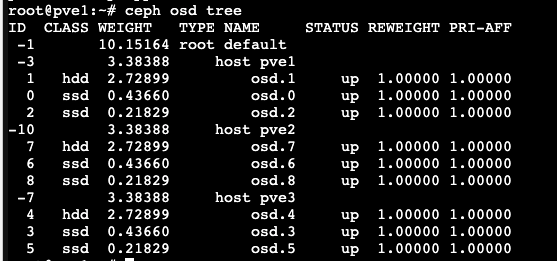
Y para terminar, aunque se irá reconstruyendo todos los datos, podemos forzar la reparación:
root@pve2:~# ceph pg ls
Habrá que repetir este comando en cada bloque:
root@pve2:~# ceph pg repair 2.0
instructing pg 2.0 on osd.4 to repair
En unas horas, todo estará en verde…
¿Te ha gustado la entrada SÍGUENOS EN TWITTER?
¿Te ha gustado la entrada SÍGUENOS EN TWITTER O INVITANOS A UN CAFE?