 Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue
Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue

Artículos relacionados
Solución Error Failover Cluster Partitioned
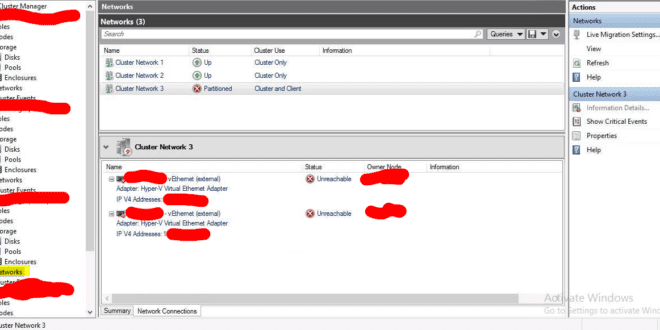
El otro día nos encontramos con un error bastante curioso que tenía que ver con un clúster de dos máquinas Hyper-V en Windows Server 2016 Core. Entre ellas existe una Failover Clúster y revisando otros temas nos encontramos que la consola del Failover en el apartado Networks ponía que estaba Partitioned.
Si queréis saber algo más sobre este error podéis mirar esta entrada:
https://blogs.technet.microsoft.com/askcore/2011/08/08/partitioned-cluster-networks/
Básicamente, lo que parece es un problema de comunicación entre los hosts. Os cuento y veréis que eso no parece ser del todo cierto.
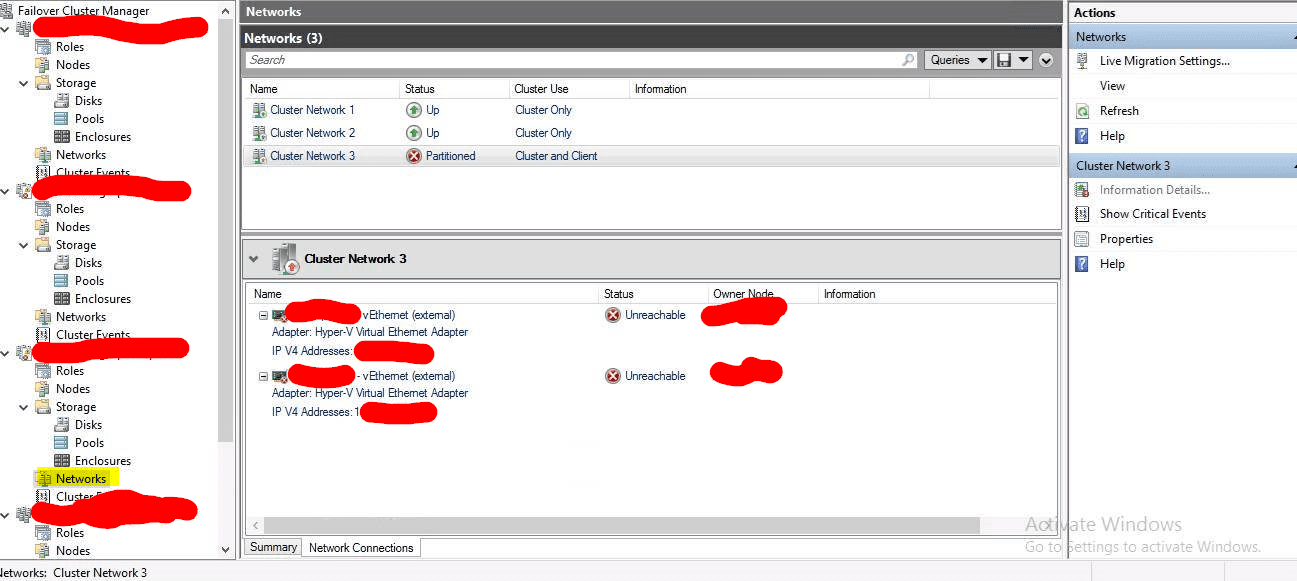
Nos pasó sobre unos nodos que no tienen máquinas virtuales actualmente, constan de un Teaming entre dos interfaces a 10G conectadas a switchs Meraki. Cuando vamos al visor de eventos nos encontramos con un error que dice algo como esto:
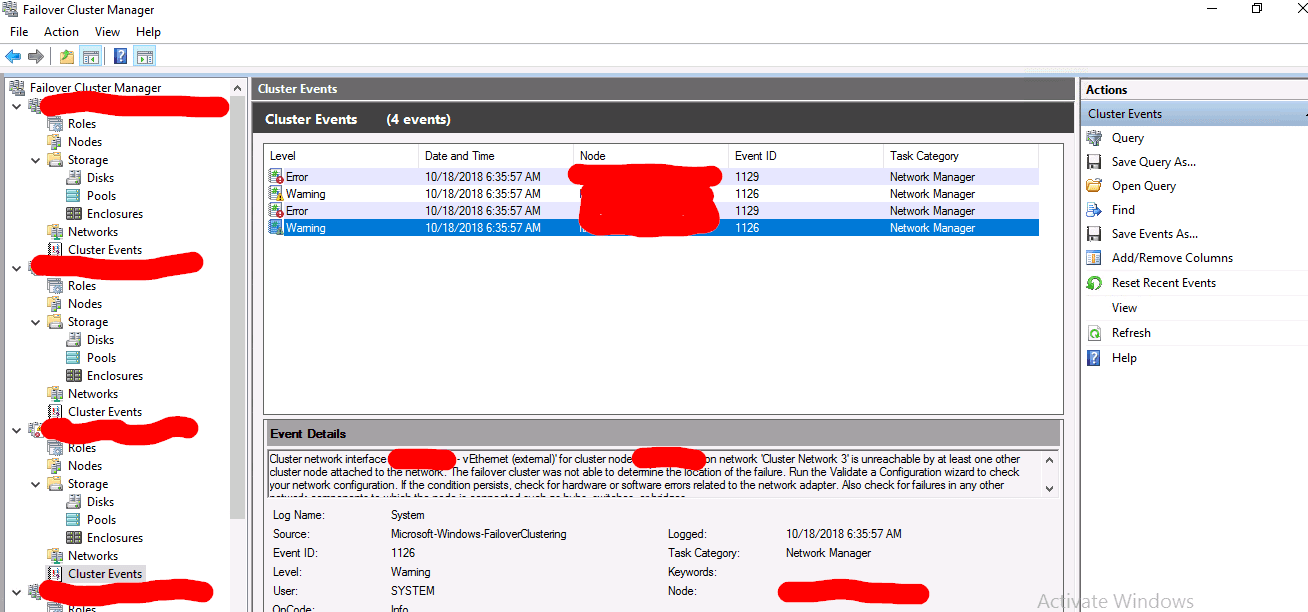
EVENT ID: 1126 – Warning:
Cluster network interface ‘nodo01 – vEthernet (external)’ for cluster node ‘nodo01’ on network ‘Cluster Network 3’ is unreachable by at least one other cluster node attached to the network. The failover cluster was not able to determine the location of the failure. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Y en el mismo segundo el siguiente:
EVENT ID: 1129 – Error:
Cluster network ‘Cluster Network 3’ is partitioned. Some attached failover cluster nodes cannot communicate with each other over the network. The failover cluster was not able to determine the location of the failure. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges
Y esto para los dos nodos que componen el clúster….
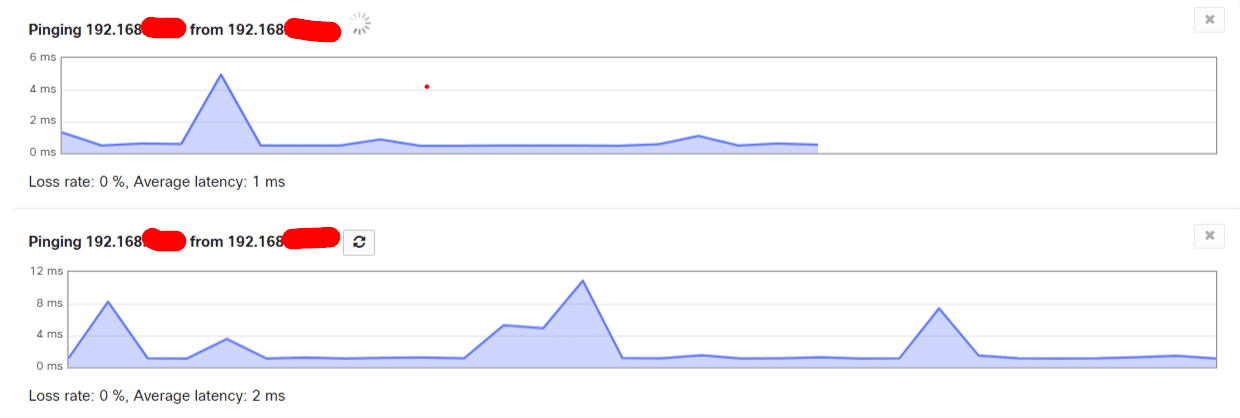
Hemos revisado Meraki para ver si vemos corte en los enlaces que componen el Teaming y no se aprecia corte en las gráficas:
A su vez hemos lanzado una validación del clúster que no ha arrojado ninguna luz tampoco:

Aparentemente, salvo por la alerta hemos realizado pruebas de todo tipo:
- Ping entre nodos
- Ping puerta de enlace
- Ping DNS
- Revisar si todos los interfaces estaban UP
- Parar cada interfaz de teaming por separado y volver a levantar
- …
Realmente el clúster parece estar bien, pero sigue alertado.
Lo único que me ha funcionado es reiniciar el VMSwitch. Es muy simple, os lo enseño por powershell:
|
1 2 3 4 5 6 7 |
# Extraemos los adaptadores Get-NetAdapter # Reiniciamos VMSwitch Restart-NetAdapter -Name "vEthernet (external)" |
Con esto todo pasa a verde…pero el misterio aún no lo se resolver por qué ha caído. Actualizaré la entrada si encuentro la solución.
¿Te ha gustado la entrada SÍGUENOS EN TWITTER?
¿Te ha gustado la entrada SÍGUENOS EN TWITTER O INVITANOS A UN CAFE?

buenas.
encontrastes la solucion? pareciera un problema en la configuracion de algun switch o a nivel redes.
pero no se todavia cual es realmente el problema