Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue
Blog Virtualizacion Tu Blog de Virtualización en Español. Maquinas Virtuales (El Blog de Negu) en castellano. Blog informática vExpert Raul Unzue

Artículos relacionados

Proxmox: Possible data damage: 1 pg recovery_unfound
Hoy voy a explicaros como solucionar un error en vuestro storage CephFS en vuestra infraestructura Proxmox.
¿Qué es en Ceph un PG (Placement Groups)?
Antes de explicar el error, lo que voy a hacer es intentar explicar qué es un PG (Placement Groups) o Grupo de Ubicación. A grandes rasgos, son parte fundamental de un clúster Ceph, ya que permiten su escabilidad y son fundamentales para su rendimiento. Al colocar datos en el clúster Ceph, los objetos se asignan a un PG y a su vez estos se asignan a OSD. Esto reduce la cantidad de metadatos por objeto.
Dependiendo del nivel de replicación de un clúster Ceph, cada PG se replica y distribuye en más de un OSD del clúster. Se podría decir que un PG es como un contenedor lógico que contiene varios objetos, de modo que este contenedor lógico se asigna a múltiples OSD.
Sin PG, sería difícil administrar y rastrear decenas de millones de objetos que se replican y se extienden por cientos de OSD.

Una vez explicado por encima vamos al error.
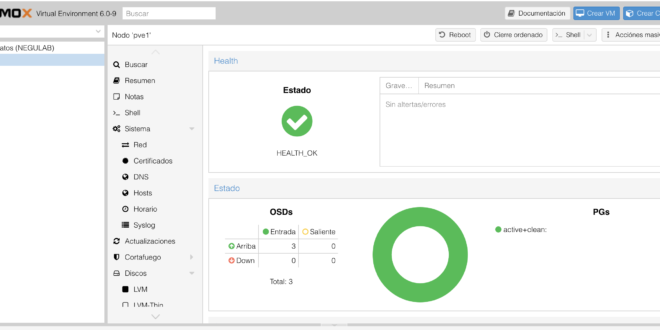
El error es “Possible data damage: 1 pg recovery_unfound”. Yo personalmente lo he visto vía gráfica, así que os explico como analizar el problema y cual es la solución que yo he encontrado:

Para revisarlo vía comando he utilizado por ssh:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@pve1:~# ceph health detail HEALTH_ERR 1/19239 objects unfound (0.005%); Possible data damage: 1 pg recovery_unfound; Degraded data redundancy: 3/57717 objects degraded (0.005%), 1 pg degraded; 1 pgs not deep-scrubbed in time; 1 pgs not scrubbed in time OBJECT_UNFOUND 1/19239 objects unfound (0.005%) pg 1.10 has 1 unfound objects PG_DAMAGED Possible data damage: 1 pg recovery_unfound pg 1.10 is active+recovery_unfound+degraded, acting [1,2,0], 1 unfound PG_DEGRADED Degraded data redundancy: 3/57717 objects degraded (0.005%), 1 pg degraded pg 1.10 is active+recovery_unfound+degraded, acting [1,2,0], 1 unfound PG_NOT_DEEP_SCRUBBED 1 pgs not deep-scrubbed in time pg 1.10 not deep-scrubbed since 2019-10-01 21:52:22.943355 PG_NOT_SCRUBBED 1 pgs not scrubbed in time pg 1.10 not scrubbed since 2019-10-06 16:17:28.577600 |
Resumo mi clúster Ceph:
|
1 2 3 4 5 6 7 8 9 10 |
root@pve1:/var/lib/ceph/osd/ceph-0# ceph df RAW STORAGE: CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 8.2 TiB 8.0 TiB 214 GiB 217 GiB 2.59 TOTAL 8.2 TiB 8.0 TiB 214 GiB 217 GiB 2.59 POOLS: POOL ID STORED OBJECTS USED %USED MAX AVAIL cephfs_data 1 71 GiB 19.22k 214 GiB 2.69 2.5 TiB cephfs_metadata 2 461 KiB 22 2.8 MiB 0 2.5 TiB |
Comprobamos que el grupo no está en un estado “obsoleto” o stale
|
1 |
root@pve1:/var/lib/ceph/osd/ceph-0# ceph pg ls |
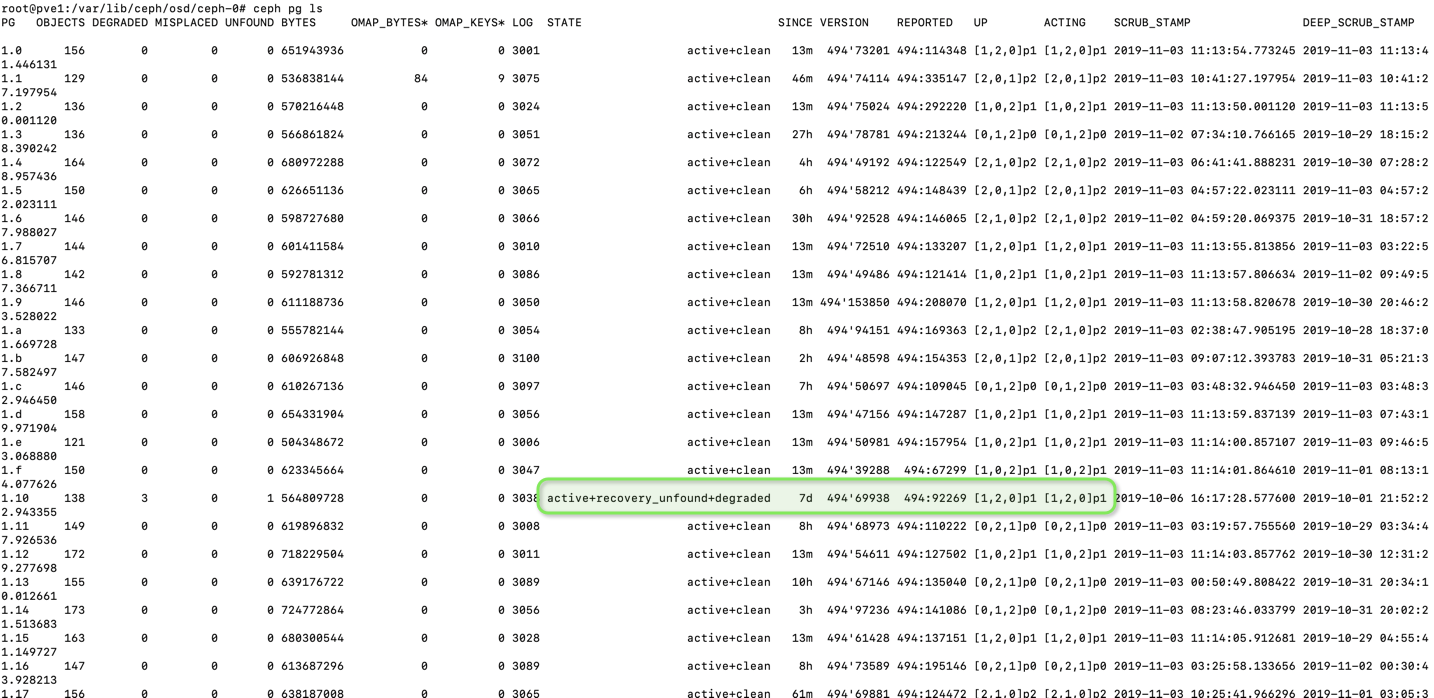
Podéis revisar el estado con este comando:
|
1 2 3 |
root@pve1:/var/log/ceph# ceph pg dump | grep ^1.10 dumped all 1.10 69 1 3 0 1 278548480 0 0 3073 3073 active+recovery_unfound 2019-11-03 12:09:10.281595 498'70173 502:92861 [1,2,0] 1 [1,2,0] 1 64'6779 2019-10-06 16:17:28.577600 64'6779 2019-10-01 21:52:22.943355 |
He descubierto que mi problema está en máquinas virtuales que no he generado o movido bien entre cambios de versión, y han dejado rastro en el storage.
|
1 2 |
root@pve1:~# ceph pg 1.10 mark_unfound_lost delete pg has 1 objects unfound and apparently lost marking |
Y después de este comando, nos encontraremos que la infraestructura está HEALTH_OK:
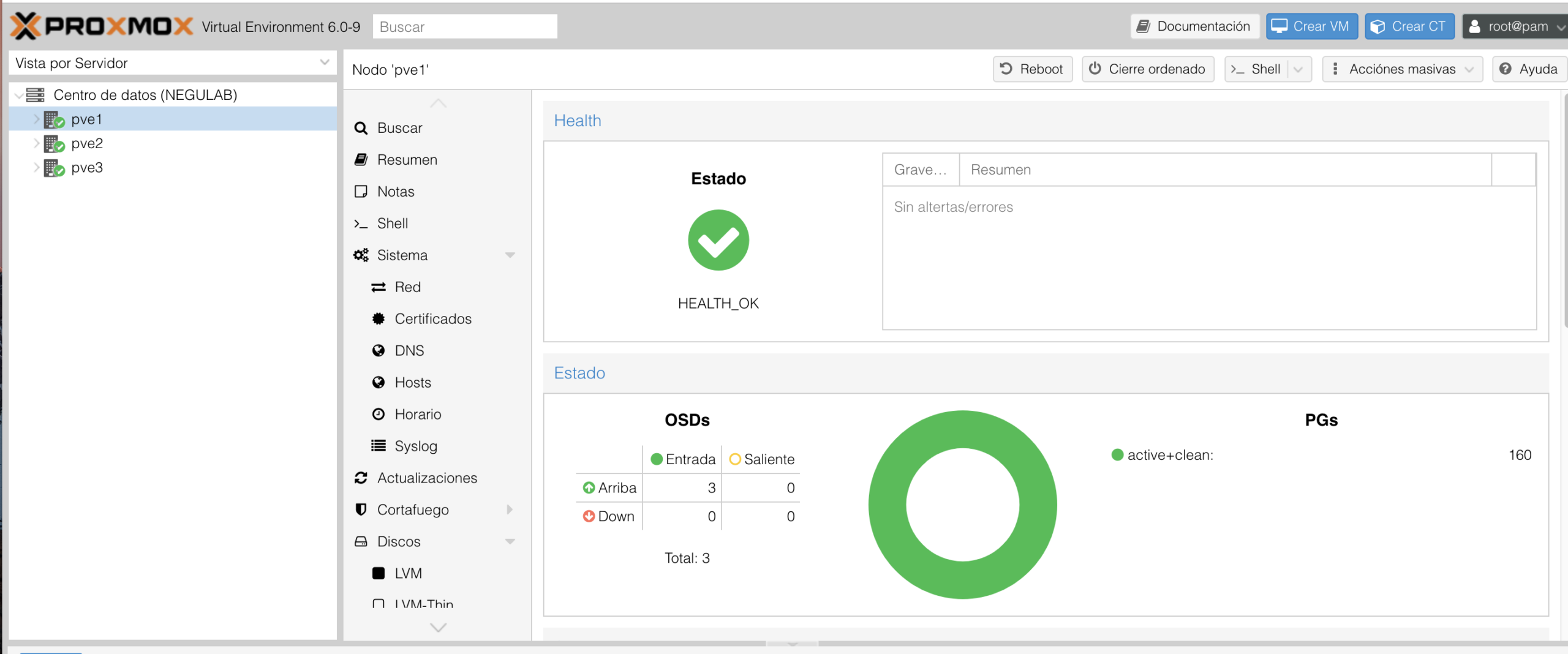
Revisado vía comando:
|
1 2 |
root@pve1:~# ceph health detail HEALTH_OK |
¿Te ha gustado la entrada SÍGUENOS EN TWITTER?
¿Te ha gustado la entrada SÍGUENOS EN TWITTER O INVITANOS A UN CAFE?